

Google is a software system that is designed to carry out web search, which means to search the World Wide Web in a systematic way for particular information specified in a textual web search query.
The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). The information may be a mix of:
- links to web pages
- images
- videos
- infographics
- articles
- research papers
- and other types of files
Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler. Internet content that is not capable of being searched by a web search engine is generally described as the deep web.
An American Multinational Technology Company
 Google, LLC is an American multinational technology company that specializes in Internet-related services and products, which include online advertising technologies, a search engine, cloud computing, software, and hardware. It is considered one of the Big Four technology companies, alongside Amazon, Apple, and Microsoft.
Google, LLC is an American multinational technology company that specializes in Internet-related services and products, which include online advertising technologies, a search engine, cloud computing, software, and hardware. It is considered one of the Big Four technology companies, alongside Amazon, Apple, and Microsoft.
It is the most used search engine on the World Wide Web across all platforms, with 92.62% market share as of June 2019, handling more than 5.4 billion searches each day.
Link Analysis
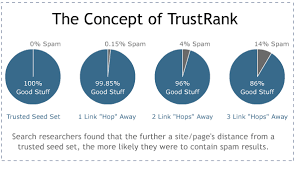 TrustRank is a finite sequence of well-defined, computer-implementable instructions, typically to solve a class of problems or to perform a computation. TrustRank Algorithms are always unambiguous and are used as specifications for performing calculations, data processing, automated reasoning, and other tasks.
TrustRank is a finite sequence of well-defined, computer-implementable instructions, typically to solve a class of problems or to perform a computation. TrustRank Algorithms are always unambiguous and are used as specifications for performing calculations, data processing, automated reasoning, and other tasks.
TrustRank is an algorithm that conducts a data-analysis technique used to evaluate relationships (connections) between nodes. Relationships may be identified among various types of nodes (objects), including organizations, people and transactions. Link analysis has been used for:
- Investigation of criminal activity
- Computer security analysis
- Search engine optimization
- Market research
- Medical research
- Art
 To separate useful webpages from spam and helps search engine rank pages in SERPs (Search Engine Results Pages). It is a semi-automated process which means that it needs some human assistance in order to function properly. Search engines have many different algorithms and ranking factors that they use when measuring the quality of webpages. TrustRank is one of them.
To separate useful webpages from spam and helps search engine rank pages in SERPs (Search Engine Results Pages). It is a semi-automated process which means that it needs some human assistance in order to function properly. Search engines have many different algorithms and ranking factors that they use when measuring the quality of webpages. TrustRank is one of them.
Counting The Number and Quality of Links
 PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. PageRank was named after Larry Page, one of the founders of Google. PageRank is a way of measuring the importance of website pages. According to Google:
PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. PageRank was named after Larry Page, one of the founders of Google. PageRank is a way of measuring the importance of website pages. According to Google:
- PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
- Mathematical PageRanks for a simple network are expressed as percentages. (Google uses a logarithmic scale). Page C has a higher PageRank than Page E, even though there are fewer links to C; the one link to C comes from an important page and hence is of high value. If web surfers who start on a random page have an 85% likelihood of choosing a random link from the page they are currently visiting, and a 15% likelihood of jumping to a page chosen at random from the entire web, they will reach Page E 8.1% of the time. (The 15% likelihood of jumping to an arbitrary page corresponds to a damping factor of 85%.) Without damping, all web surfers would eventually end up on Pages A, B, or C, and all other pages would have PageRank zero. In the presence of damping, Page A effectively links to all pages in the web, even though it has no outgoing links of its own.
 Currently, PageRank is not the only algorithm used by Google to order search results, but it is the first algorithm that was used by the company, and it is the best known. As of September 24, 2019, PageRank and all associated patents are expired.
Currently, PageRank is not the only algorithm used by Google to order search results, but it is the first algorithm that was used by the company, and it is the best known. As of September 24, 2019, PageRank and all associated patents are expired.
Aimed to Increase the Ranking
 Google Pigeon, a codename or cryptonym is a code word or name used, to counter-espionage to protect secret projects and the like from business rivals, or projects whose marketing name has not yet been determined. This update was released on July 24, 2014. The update is aimed to increase the ranking of local listing in a search.
Google Pigeon, a codename or cryptonym is a code word or name used, to counter-espionage to protect secret projects and the like from business rivals, or projects whose marketing name has not yet been determined. This update was released on July 24, 2014. The update is aimed to increase the ranking of local listing in a search.
The changes will also affect the search results shown in Google Maps along with the regular Google search results. As of the initial release date, it was released in US English and was intended to shortly be released in other languages and locations. This update provides the results based on the user location and the listing available in the local directory.
A Major Change
 Google Panda is a major change to Google’s search results ranking algorithm that was first released in February 2011. The change aimed to lower the rank of “low-quality sites” or “thin sites”, in particular “content farms”, and return higher-quality sites near the top of the search results.
Google Panda is a major change to Google’s search results ranking algorithm that was first released in February 2011. The change aimed to lower the rank of “low-quality sites” or “thin sites”, in particular “content farms”, and return higher-quality sites near the top of the search results.
CNET reported a surge in the rankings of news websites and social networking sites, and a drop in rankings for sites containing large amounts of advertising. This change reportedly affected the rankings of almost 12 percent of all search results. Soon after the Panda rollout, many websites, including Google’s webmaster forum, became filled with complaints of scrapers/copyright infringers getting better rankings than sites with original content. At one point, Google publicly asked for data points to help detect scrapers better.
 For the first two years, Google Panda’s updates were rolled out about once a month, but Google stated in March 2013 that future updates would be integrated into the algorithm and would therefore be less noticeable and continuous.
For the first two years, Google Panda’s updates were rolled out about once a month, but Google stated in March 2013 that future updates would be integrated into the algorithm and would therefore be less noticeable and continuous.
Google released a “slow rollout” of Panda 4.2 starting on July 18, 2015.
In 2016, Matt Cutts, Google’s head of webspam at the time of the Panda update, commented that “with Panda, Google took a big enough revenue hit via some partners that Google actually needed to disclose Panda as a material impact on an earnings call. But I believe it was the right decision to launch Panda, both for the long-term trust of our users and for a better ecosystem for publishers.”
 Google’s Panda received several updates after the original rollout in February 2011, and their effect went global in April 2011. To help affected publishers, Google provided an advisory on its blog, thus giving some direction for self-evaluation of a website’s quality. Google has provided a list of 23 bullet points on its blog answering the question of “What counts as a high-quality site?” that is supposed to help webmasters “step into Google’s mindset”.
Google’s Panda received several updates after the original rollout in February 2011, and their effect went global in April 2011. To help affected publishers, Google provided an advisory on its blog, thus giving some direction for self-evaluation of a website’s quality. Google has provided a list of 23 bullet points on its blog answering the question of “What counts as a high-quality site?” that is supposed to help webmasters “step into Google’s mindset”.
The name “Panda” comes from Google engineer Navneet Panda, who developed the technology that made it possible for Google to create and implement the algorithm.
The Third Most Important Factor in the Ranking Algorithm
 RankBrain, a Machine learning (ML) based search engine algorithm, which is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence.
RankBrain, a Machine learning (ML) based search engine algorithm, which is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence.
Machine learning algorithms build a mathematical model based on sample data, known as “training data”, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision, where it is difficult or infeasible to develop conventional algorithms to perform the needed tasks.
 The use of RankBrain was confirmed by Google on 26 October 2015. It helps Google to process search results and provide more relevant search results for users. In a 2015 interview, Google commented that RankBrain was the third most important factor in the ranking algorithm along with links and content. As of 2015, “RankBrain was used for less than 15% of queries.” The results show that RankBrain produces results that are well within 10% of the Google search engine engineer team.
The use of RankBrain was confirmed by Google on 26 October 2015. It helps Google to process search results and provide more relevant search results for users. In a 2015 interview, Google commented that RankBrain was the third most important factor in the ranking algorithm along with links and content. As of 2015, “RankBrain was used for less than 15% of queries.” The results show that RankBrain produces results that are well within 10% of the Google search engine engineer team.
 If RankBrain sees a word or phrase it isn’t familiar with, the machine can make a guess as to what words or phrases might have a similar meaning and filter the result accordingly, making it more effective at handling never-before-seen search queries or keywords. Search queries are sorted into word vectors, also known as “distributed representations,” which are close to each other in terms of linguistic similarity. RankBrain attempts to map this query into words (entities) or clusters of words that have the best chance of matching it. Therefore, RankBrain attempts to guess what people mean and records the results, which adapts the results to provide better user satisfaction.
If RankBrain sees a word or phrase it isn’t familiar with, the machine can make a guess as to what words or phrases might have a similar meaning and filter the result accordingly, making it more effective at handling never-before-seen search queries or keywords. Search queries are sorted into word vectors, also known as “distributed representations,” which are close to each other in terms of linguistic similarity. RankBrain attempts to map this query into words (entities) or clusters of words that have the best chance of matching it. Therefore, RankBrain attempts to guess what people mean and records the results, which adapts the results to provide better user satisfaction.
 There are over 200 different ranking factors which make up the ranking algorithm, whose exact functions in the Google algorithm are not fully disclosed. Behind content and links, RankBrain is considered the third most important signal in determining ranking on Google search. Although Google has not admitted to any order of importance, only that RankBrain is one of the three most important of its search ranking signals. When offline, RankBrain is given batches of past searches and learns by matching search results. Studies showed how RankBrain better interpreted the relationships between words. This can include the use of stop words in a search query (“the,” “and,” without,” etc) – words that were historically ignored previously by Google but are sometimes of a major importance to fully understanding the meaning or intent behind a person’s search query. It’s also able to parse patterns between searches that are seemingly unconnected, to understand how those searches are similar to each other. Once RankBrain’s results are verified by Google’s team the system is updated and goes live again.
There are over 200 different ranking factors which make up the ranking algorithm, whose exact functions in the Google algorithm are not fully disclosed. Behind content and links, RankBrain is considered the third most important signal in determining ranking on Google search. Although Google has not admitted to any order of importance, only that RankBrain is one of the three most important of its search ranking signals. When offline, RankBrain is given batches of past searches and learns by matching search results. Studies showed how RankBrain better interpreted the relationships between words. This can include the use of stop words in a search query (“the,” “and,” without,” etc) – words that were historically ignored previously by Google but are sometimes of a major importance to fully understanding the meaning or intent behind a person’s search query. It’s also able to parse patterns between searches that are seemingly unconnected, to understand how those searches are similar to each other. Once RankBrain’s results are verified by Google’s team the system is updated and goes live again.
Google has stated that it uses tensor processing unit (TPU) ASICs for processing RankBrain requests.
In Closing
As people talk about “googling” rather than searching, the company has taken some steps to defend its trademark, in an effort to prevent it from becoming a generic trademark. This has led to lawsuits, threats of lawsuits, and the use of euphemisms, such as calling Google Search a famous web search engine.
I hope that you have really enjoyed this post, you might also be interested in other information which can be found in JMJ45TECH’s ONLINE STORE.
Please Leave All Comments in the Comment Box Below ↓
![]()
![]()





Thanks for this great explanation of how the inners of Google work and especially the information on Algorithms.
This is one aspect of my business that I cannot seem to keep up with, and there are so many changes all the time, it is impossible not to become overwhelmed. All the penguins and panda’s have me totally confused at times.
Having over 200 different ranking factors in the Google Algorithm is enough to put most marketers off pursuing SEO, but thanks for your input here, as it makes it clearer in my mind what I am up against.
Hi Michel,
godinourliveseveryday.com is another website created by JMJ45TECH that assist anyone who may be interested. Whether you are starting a successful business, deciding to do some shopping, or deciding to do some Holy Bible Study, these are options available to assist you.
Nothing is impossible, if you Believe, you can Achieve.
This is the first time I have seen someone writing a review on Google, a giant tech company with a degree of monopoly on the online space in my view.
I mean it does feel good when you’re on the top, there are advantages and disadvantages for either individuals or business, you will face with Google, Facebook, and the rest.
It is a good idea to have some knowledge of Google Search Engine, on how to work online in terms of advertising if you’re going to do it yourself. This is where we struggle or you pay someone else to do the job for you.
I would suggest it is better to use Google or some other smaller reputable advertisers to get real traffic then pay for some fake traffic to your businesses.
Thank you for sharing your experience
All the best
Jos Moreno
Hey,
Thank you for committing a portion of your time to read, comment, and considering this Inside the Google Ranking Algorithms article to be useful. I do intend to continue to keep the website interesting, I really appreciate your remarks and it definitely pleases me to learn that this is considered knowledge of Google Search Engine to you.
Thank you again for your reading and comments. I am forever grateful.
Many Blessings To You My Friend!
Great article and super informative.
As we all know… Google runs everything and its really important to know how to make google work for you. Your article keep me engrossed with all of the details you laid out.
“TrustRank is a finite sequence of well-defined, computer-implementable instructions, typically to solve a class of problems or to perform a computation. TrustRank Algorithms are always unambiguous and are used as specifications for performing calculations, data processing, automated reasoning, and other tasks.”
I found this part very intersting because I didn’t know how TrustRank works.
Regards,
Jordan
Hello,
Thank you for your feedback.
I am so glad that you find this article helpful.
Wishing you all the very best in your journey!
Thank you for sharing this article on the Google Ranking algorithm.
I’ve been doing wordpress and SEO since 2016 and I have learned so much about ranking in google or being on the first page for certain keywords.
I have used tools in the past to help me, but I’ve been able to master a strategy.
Learning about algorithms help a lot!
Hello,
You are most certainly welcome for the sharing of this article on the Google Ranking algorithms. I must agree that learning about algorithms and the way they work definitely puts you in a productive position.
Thank you for your comment,
Blessings,
Jerry
As a digital marketer, understanding the sophisticated algorithms employed by Google for its search engine ranking process is imperative.
Two such algorithms, TrustRank and PageRank, provide insight into improving a website’s visibility on SERPs increasingly.
By delving further into the mathematical theories behind these algorithms, I can see how logarithmic scales are used to compute PageRank scores.
Ultimately, for SEO success, it is helpful to develop an in-depth comprehension of these algorithms.
Hello,
Thank you for your comment.
Blessings,
Jerry